What is Apache Storm?
- A real time big data processing system
- Stream based
- Fault tolerant and distributed
- Non persistent
- Written in Clojure and some Java
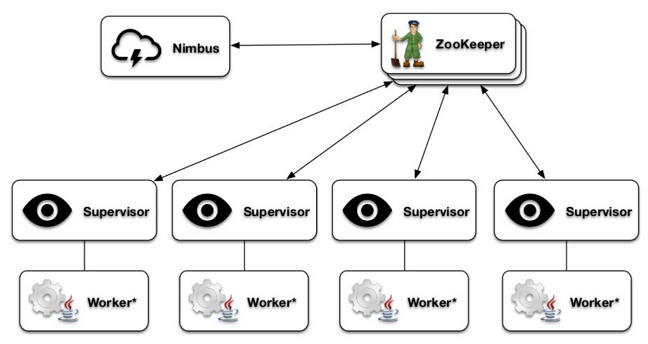
- Master / save plus ZooKeeper
- Big Data Analysis
Apache Storm vs Hadoop
Hadoop
- Batch / file based
- Distributed and fault tolerant
- Master / save plus ZooKeeper
- persistent, use HDFS
- Big Data Analysis
Hadoop and Storm are complementary technologies, and can be used in a single system. Storm processes real time streams of data, and Hadoop processes batched data on HDFS.
Apache Storm terms
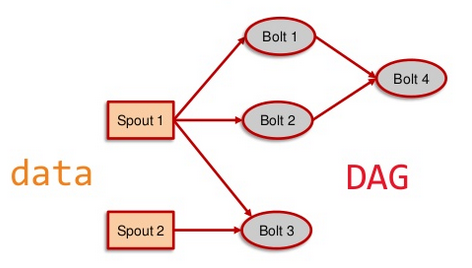
Tuple – an ordered list of elements
Stream – an unbounded feed of tuples
Spout – a source of streams
Bolt – functions/ filters to process streams
Topologies – ETL like architecture built from sprouts, Streams, Bolts
Nimbus – master node
supervisor – controls worker progresses
Other abstractions on top of Storm
Storm Trident, Storm DRPC
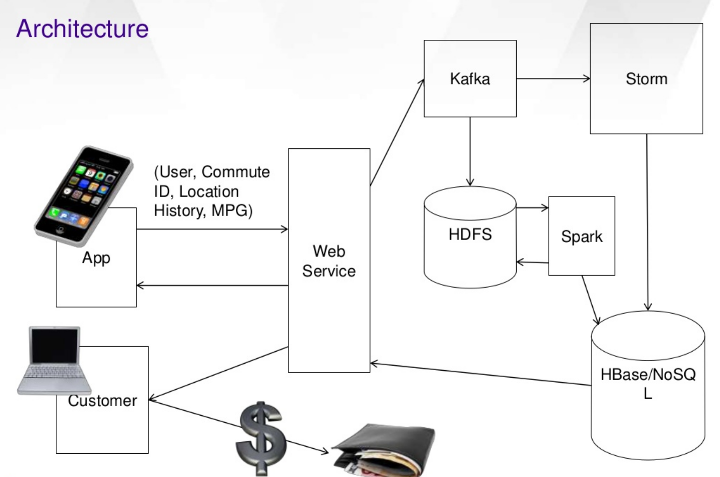
Physical View